目标
- Implement a neural network with fc layers for classifiction
- Test it on CIFAR-10 dataset
初始化
auto-reloading external modules
定义relative error
1 | def rel_error(x, y): |
- 这里插入一下np.max和np.maximum的区别
- max是求序列的最值,可以输入一个参数,axis表示的是求最值的方向
- maximum至少输入两个参数,会把两个参数逐位比较,然后输出比较大的那个结果
- 但是好像在这里的使用上面,说明x和y不是一个单独的值,应该是两个数组
1 | >> np.max([-4, -3, 0, 0, 9]) |
不是很理解这里为什么要除以x+y
设置参数
cs231n/classifiers/neural_net.pyself.params储存了需要的参数,参数都被存储在dict里面,一个名字对应一个内容
两层神经网络的参数如下:
- W1,第一层的weights,(D,H),其中H是第二层的neruon的个数。因为只有一层的时候,D个输入对应C个输出,现在有两层的fc,对应的输出就是第二层的units个数
- b1,第一层的bias,(H,)
- W2,第二层的weights,(H,C)
- b2,第二层的bias
bias都需要初始化为相应大小的0,weights初始化成0-1之间的比较小的数字
Forward pasa
计算scores
- 这部分非常简单,两次Wx+b,并且在第一次之后记得激活就可以了
- 激活函数用的relu,内容就是score小于0的部分让他直接等于0
计算loss
- 这里用的是softmax计算loss,和softmax的作业内容一样,将所有的scores exp,求占的百分比,求出来的部分-log,然后把所有的求和
- 这里用到了boardcasting的问题,注意(100,1)这样的才可以boardcasting,(100,)的是一维数组,需要把它reshape成前面的样子才可以
- 这里最后的结果还总是差一点,最后发现是因为regularzation的时候多乘了0.5,看题呜呜呜
Backward pass
- 由于b是线性模型的bias,偏导数是1,直接对class的内容求和然后除以N就是最终结果
- 对W求导的时候需要用到链式法则,然后直接代码实现一下就行了
- 这里遇到的主要问题是loss的值会影响他估计的值,因为loss的regularzation改了,所以答案一直对不上。
Training predict
- 训练和之前写的差不多,训练网络,主要包括写training部分的随机mini-batch和更新weights,记得lr更新的时候要带负号
- 预测也差不多,算出来scores,找到最大的score就是分类的结果。注意找最大的时候要用argmax,找到的是最大的东西的indice,不然得到的是得分
1
2
3
4
5
6
7
8
9
10
11
12
13net = init_toy_model()
stats = net.train(X, y, X, y,
learning_rate=1e-1, reg=5e-6,
num_iters=100, verbose=False)
print('Final training loss: ', stats['loss_history'][-1])
# plot the loss history
plt.plot(stats['loss_history'])
plt.xlabel('iteration')
plt.ylabel('training loss')
plt.title('Training Loss history')
plt.show()
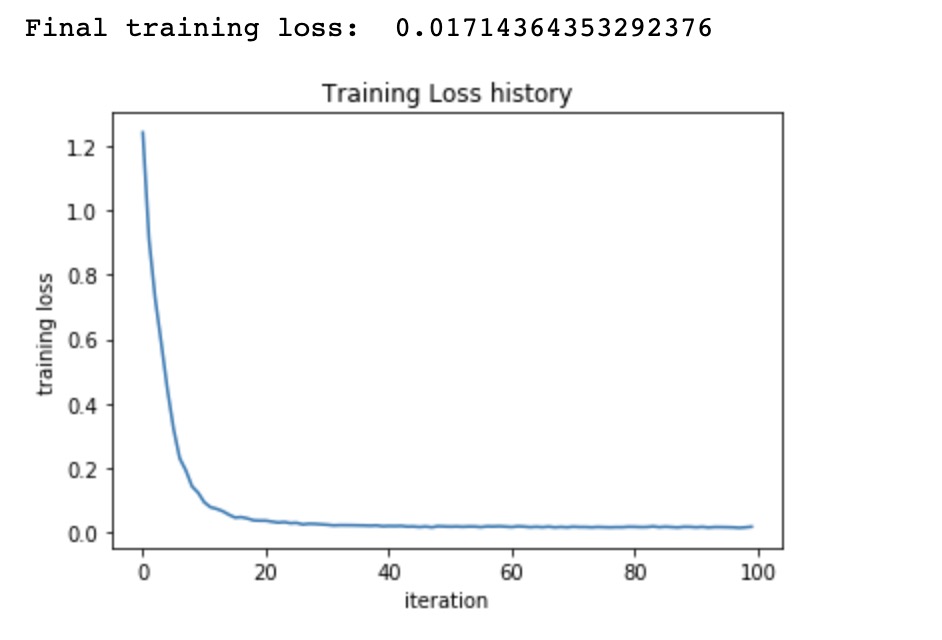
使用写好的来训练CIFAR-10
1 | input_size = 32 * 32 * 3 |
这时候得到的准确度应该在28%左右,可以优化
进一步优化
- 一种可视化的方法是可视化loss function和准确率的关系,分别在训练和val集上面
- 另种是可视化第一层的weights
两种方法的结果如下: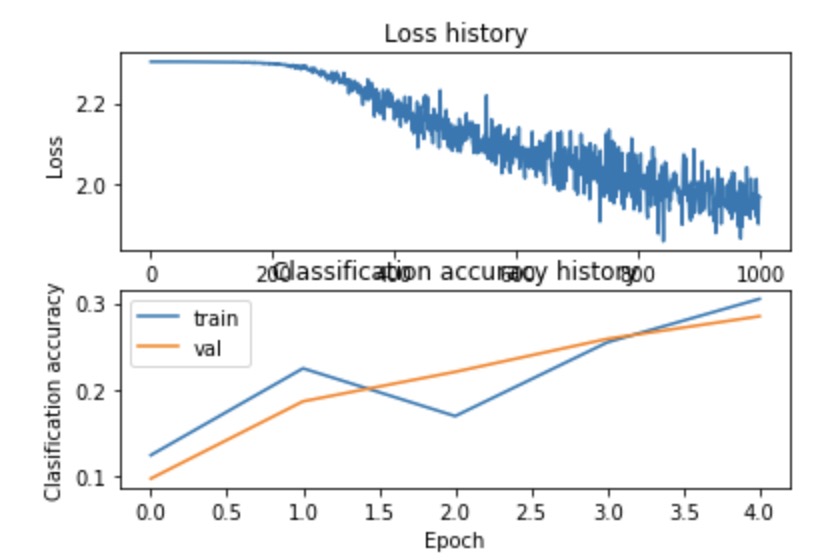

debug模型
- 问题
- loss大体上都是linearly的下降的,说明lr可能太低了
- 在training和val的准确率上没有gap,说明model的容量太小的,需要增大size
- 如果容量过大还会导致overfiiting,这时候gap就会很大
- tuning hypers
- 题目里面的建议是tuning几个hyper,还是和之前一样,直接random,search
- 这里选了三个参数,分别是units的数量,learning rate和reg的强度,随便设置了一下界限
- 最终计算出来的val准确率是:49.5% 秀秀秀!!
- 可视化weigh之后的结果是

- 震惊,居然最后的测试正确率也达到了49.4!!!
1 | best_net = None # store the best model into this |
代码部分
nerual_net.py部分的完整代码如下
1 | from __future__ import print_function |