相关介绍链接
koike lab
关于opencv的fisheye calibration:http://ninghang.blogspot.com/2012/08/fish-eye-camera-calibration.html
关于calibration的视角的问题,matlab可以找到全部视角:https://www.mathworks.com/help/vision/ug/fisheye-calibration-basics.html
DeepCalib: A Deep Learning Approach for Automatic Intrinsic Calibration of Wide Field-of-View Cameras(CVMP ‘18)
使用深度学习对fish eye相机的视野进行补全。
Abstract
- 广角相机的calibration在各种各样的地方都有应用
- 3D重建
- image undistortion
- AR
- camera motion estimation
- 现在存在的calibration都需要多张图片进行校准(chessboard)
- 提出了一种完全自动的标定方法,基于CNN
- 在网上找了非常多的omnidirectional的图片进行训练,生成了具有100多万张图片的dataset
Intro
- 广角相机的calibration最重要的是测量
- intrinsic parameters
- 两个wide FOV的重要参数:focal length & distortion parameter
- 现存的calibration方法有很多限制:
- 需要一个object的多个角度的观察
- 需要观察一个特定的structures
- 在多张图片中观察相机的移动
- 现在最有名的方法是chessboard
- 他们提出的方法可以解决上述的问题,并且针对网上下下来的照片也可以用
主要方法
- 一个CNN with Inception-V3 architecture
- 目标
- 收集具有不同intrinsic parameters的图片,然后自动生成具有不同的focal length和distortion的图片(没懂)
- 对比不同的CNN结构
related work
- 以前存在的calibration方法主要可以分成四个不同的部分
- 最常使用的就是棋盘一类的,需要观察一张图片的不同部分,从而得到结果。问题主要是出在比价麻烦,而且无法对野生的照片进行calibration
- 基于图片上面的geometric structure,line,消失的点等。不能处理general environments
- self-calibration(自身还有一些容易收到影响的问题)
- 需要多张图片
- 需要camera motion estimation
- 基于DL的,但是都是解决了部分问题
- 没有把参数全都估计出来
- dataset是从prespective的图片生成回来的,会有不完整的部分(但是他们的很完整而且会有很多应用)
Approach
选择model -> 自动生成large-scale dataset -> network的structure
Projection & distrotion model(考虑生成dataset的机器)
- 广角相机需要具体的projection model把3D的世界map到图片里面去
- 考虑了几个model
- Brown-Conrady’s model(1971)
- 在实际应用里面不适合广角相机的大的distortion
- hardly reversible
- division model [Fitzgibbon 2001]
- 只是为了fisheye设计的,对相机没有普适性
- impossible to revert
- Brown-Conrady’s model(1971)
- 这篇文章里面的model
- unified spherical model [Barreto 2006; Mei and Rives 2007]
- 原因
- fully reversible
- 可以解决很大的distortion
- projection和back-projection都admit closed-form solution -> 计算效率非常高(没怎么看懂)
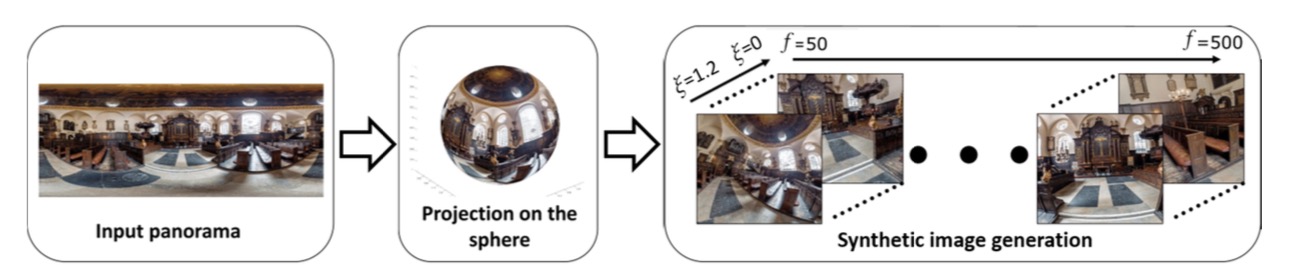
generation dataset
- 因为根本做不到并且还没有那么大的dataset,所以他们打算人工合成一些(synthetically)
- 没有选择用prspective的图片生成
- 在普通的图片里面加上distortion会把图片里应该看不到的地方看到(边缘都会变成黑色的) -> 生成的图片不真实
- 使用panoramas得到图片
- 因为全景图都是360度的,那么多少度的广角都能驾驭
- 可以假设把相机放在任何地方
- 对于给的一张全景图,可以自动生成不同焦距,不同distortion的图片,这样就得到了很大的dataset
network architecture
- Inception-V3 structure
- 基于上面的,实践了三种不同的网络
- 一层网络,输出两个不同的结果,一个是f一个是distortion
- DualNet,由两个独立网络组成,一个输出f,一个输出distortion,这两个值是相互独立的。
- SeqNet,两个连在一起的网络,先从A网络里得到f,再把图片和f放进B得到最终的distortion
- 解决问题:
- classification
- regression
result
net的参数
- net在imageNet上面pre-train了,然后再进行了进一步的训练
evaluation
对比上面不同三个网络的performance
user study
估计出来的结果很难说明到底是不是成功的undistort了,所以设计了user study
Combining Multiple Depth Cameras and Projectors for Interactions On, Above, and Between Surfaces(‘2010)
感觉算是比较最早的SAR的部分,重点就是用多个视角的depth camera来捕捉用户的动作,完成相应的交互,不知道在桌子上的投影和在墙上的投影是怎么实现的
abstract
- 可以交互的displays和surface
- 可以投影到非常规的投影表面上面去
- 可以把这些东西扔来扔去,之类的
Intro
- the user may touch to manipulate a virtual object projected on an un-instrumented table(这个现在已经不新鲜了)
- office size room
- depth camera的妙用
- 这个空间的任何地方都是surface,都可以投影
- 整个空间是一个大的电脑
- 可以投影到user自己的身上去-> 可以投影到用户的手上
- 3D mesh data
硬件构成:multiply的depth camera& projector
支持的interaction
- 可以交互的非显示器部分(比如墙壁或者桌子)
- 所有的部分可以连接成一个可交互的部分,可以通过肢体来进行两个屏幕之间的交互(同时摸这两个东西他就会换位置)
- 可以从display上面pick up出东西来
- 检测出用户的动作来,支持动作的交互
implement
- 在天花板上装了三个depth camera和三个projector,可以看到交互的地方,不需要特别精准的calibration
- PrimeSense camera,有IR和RGBcamera
- depth image可以用来分离静止的物体
calibration
- both the cameras and the projectors are registered with the real world.
- camera
- a fixed grid of retro-reflective dots
- 3D camera pose estimation de- scribed by Horn[13]
interactive space
- calibration之后camera就可以捕捉real time的3D mesh model
- 因为camera和projector一起校准过了,所以投影就可以正确的投影在相应的地方了
- 根据mesh model可以得到手的三维图形,根据这个图形就可以知道手在touch哪个地方了
- 在tracking上面用了更简单的算法:[28] [29]
- 直接对3D的mesh进行操作比较复杂,所以对2D的画面进行了操作
- virtual camera
- first transforming each point in every depth camera image from local camera to world coordinates, and then to virtual camera coordinates by virtual camera view and projection matrices.
- z方向的坐标由xy写出来 -> 把一张深度图片压成了一个2D的图片
- 结合多个角度判断用户的最终动作
- 用上方的摄像机的图片判断用户是不是同时接触两个东西了
- 空间里的mene -> 在特殊的一个地方有投影
RoomAlive: Magical Experiences Enabled by Scalable, Adaptive Projector-Camera Units(UIST ‘14)
感觉是一个比较完全的屋内投影的例子了
Abstract
- 可以动态的适应任何的屋子
- touch, shoot, stomp, dodge, steer投影上去的东西,以及和物理的环境交互
- projector-depth camera unit -> 所以就不需要特别多的calibration(可以重点看看这个unit是怎么制作的)
Intro
- 做了一个游戏系统
- projector和depth camera一体的东西
- cover the room’s walls and furniture with input/output pixels
- track用户的动作,并且根据动作在屋子里面生成对应的东西
- capture & analyze屋子里的结构,得到房间里面的墙以及地板之类的特征
- a distributed framework for tracking body movement and touch detection using optical-flow based particle tracking [4,15], and pointing using an infrared gun [19]. -> 其实还不是没有依据视觉来捕捉这个东西
- 居然装了6个相机-投影仪的unit (procam)
related work
Spatial Augmented Reality (SAR)
- use light to change appearance physical objects
- illumiroom -> 非常喜欢这个idea
- projection mapping很多都需要在特定的东西上面mapping -> 但是这个可以在整间屋子的任意部分mapping
System
- unit -> color camera + IR camera emitter + wide FOV projector + computer
- in a large living room (说明这种研究里面屋子的大小也非常的重要) + 6 units
- plug-in to the Unity3D commercial game engine (怪不得能做游戏
硬件
- wide field of view projectors
- 每个部分connected to他自己特定的电脑
- 所有的部分都装在房间的屋顶上
auto calibration
- 并不需要calibration所有的相机
- 在units之间有一部分的overlap,所以东西在校准的时候观察同一个东西就行了?
- 用opencv的校准function
- chain together所有的部分然后得到了各个相机的关系
auto scene analysis
- 所有的unit得到的深度信息,生成之后寻找连续的平面(墙,地板等等)
- Hough transform(并不会这个东西)
游戏
- unity3D的plug-in
- 游戏设计者只需要在设计界面里添加东西就行了
mapping
- 事实渲染整个东西的任务没有完全解决
- 4个技术
- content in a uniformly random way 哈。。。居然是随机投影出来的
- 针对不同类型的被投影的东西,会根据不同的原理出现在不同的地方(比如石头只会出现在地面上)
- 投影的东西针对用户现在的位置,只投在用户自己看得到的地方
- 在移动屋子里的物理物品的时候,改变屋子的部分
tracking user interface
- body movement, touching, stomping, pointing/shooting and traditional controller input
- [4,15]捕捉了depth map -> ‘proxy particles’,就是动作游戏里面的体感捕捉的算法 -> tracked by using a depth-aware optical flow algorithm
- gun的input选择了红外枪
- 也支持寻常的游戏手柄
rendering
- RoomAlive tracks the player’s head position and renders all virtual content with a two-pass view dependent rendering
这部分主要讲游戏怎么设计的
limitation
- calibration errors!这样在交叠的地方会出现重影
- system latency 延迟QAQ
- 在overlap的sensors上面解决tracking issues
Peripheral Expansion of Depth Information via Layout Estimation with Fisheye Camera( ‘16)
从RGBD鱼眼相机提取深度信息(但是这个用了多个相机的system)
abstract
- 一个普通的RGB相机和一个fish eye,把视角扩展到了180°
- developed a new method to generate scaled layout hypotheses from relevant corners, combining the extraction of lines in the fisheye image and the depth information
- overcome severe occlusions.
intro
- 主要就是把现有的RGB fisheye camera和Depth camera结合起来,得到鱼眼的深度信息
Pedestrian Detection in Fish-eye Images using Deep Learning: Combine Faster R-CNN with an effective Cutting Method(SPML ‘18)
用鱼眼相机和RCNN来检测行人(感觉这个检测的目标比较小) -> 怎么感觉挺水的
abstract
- 鱼眼相机的边缘扭曲问题 -> rotary cutting to solve the problem
- 把相机分成了边缘部分和中间部分
Method
- 裁剪图片
- 绕着鱼眼相机的中心旋转,30度,12次
- 每次旋转完截取三组图片,分别是靠边缘的和靠中心的 -> 更好检测人群(垂直的)
- 使用这些裁剪的图片training