target
- 之前的内容讲了lr的优化方法,比如Adam,另一种方法是根据改变网络的结构,make it easy to train -> batch normalization
- 想去掉一些uncorrelated features(不相关的特征),可以在训练数据之前preprocess,变成0-centered分布,这样第一层是没有问题的,但是后面的层里还是会出问题
- 所以把normalization的部分加入了DN里面,加入了一个BN层,会估计mean和standard deviation of each feature,这样重新centre和normalized
- learnable shift and scale parameters for each feature dimension
- 核心思想:粗暴的用BN来解决weights初始化的问题
ref:https://kratzert.github.io/2016/02/12/understanding-the-gradient-flow-through-the-batch-normalization-layer.html
Batch normalization: forward
这个东西的要义就是NN里面的一层,不对维度改变,但是会改变这些值的分布
首先setup,并且载入好了preprocess的数据cs231n/layers.py -> batchnorm_forward
- keep exp decay 来运行mean & variance of each feature -> 在test的时候去normalize data
- test-time: 计算sample mean和varience的时候用大量的训练数据而不是用所有图片的平均值,但是在作业里面用的是平均值,因为可以省去一步estimate(torch7 也用的是平均值)
1 | running_mean = momentum * running_mean + (1 - momentum) * sample_mean |
I/O
- input
- x,data(N,D)
- gamma:scale parameter(D,)
- beta:shift parameter(D,)
- bn_param: 一个dict
- mode:‘train’ or ‘test’
- eps:为了数字上的稳定性的一个常数
- momentum:在计算mean和variance上面的一个常数
- running mean:(D,),是running mean
- running var:(D,)
- output
- out:(N,D)
- cache:在back的时候用
todo
- 用minibatch的统计来计算mean和variance,用这两个值把data normalize,并且用gamma和beta拉伸这个值,以及shift这些值的位置
- 在分布的上面,虽然求得是running variance,但是需要normalize的时候考虑的是standard(也就是平方根)

implement
- 其实是和如何计算息息相关的,知道输入,求这个玩意的normal的步骤如下(其中的x就是这个minibatch的全部数据)
- 求mu,也就是x的mean(注意这里要对列求mean,也就是把所有图片的像素均匀分布,最后得到的结果是D个不是N个)
- 求var,知道这个东西,可以直接用 np.var(x, axis = 0)来求方差
- 求normalize: x - x.mean / np.sqrt(x.var + eps)
- 其中刚开始求出来的var就是方差,也就是标准差的平方
- eps是偏差值,这个值加上方差开方是标准差
- scale和shift,乘scale的系数,加shift的系数
- 最后需要计算什么cache和back的推导息息相关
Batch normalization: backward
- 可以直接画出来计算normal的路径,然后根据这个路径back
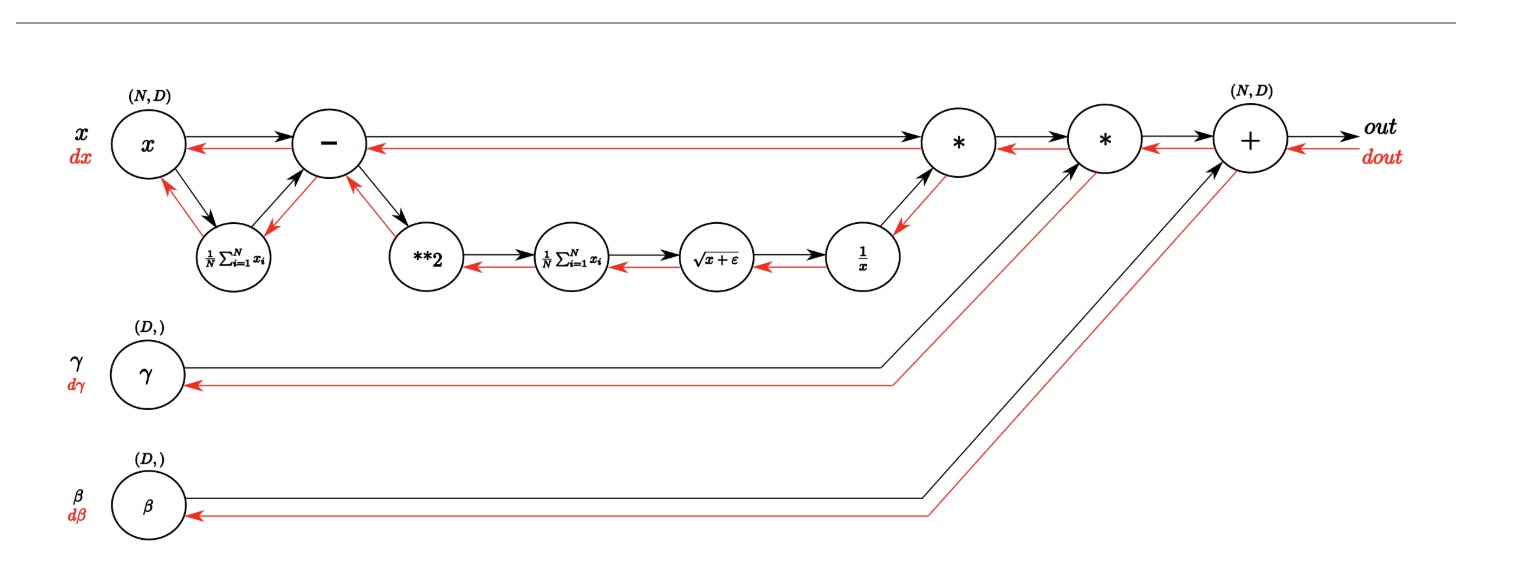
- 要义就是一步一步的求导!一步一步的链式法则
- 注意的就是求mean回来的导数,理解上来说就是这个矩阵在求导的过程中升维了,从(D,)变成了(N,D),而在最开始求得时候所有的数字的贡献都是1,所以往回走的时候乘一个(N,D)的全是1的矩阵,并且1/N的常数还在
Batch normalization: alternative backward
- 在sigmoid的back的过程中有两种不同的方法
- 一种是写出来整体计算的图(拆分成各种小的计算),然后根据这张图的再back回去
- 另一种是在纸上先简化了整体的计算过程,然后再直接实现,这样代码会比较简单
- ref:https://kevinzakka.github.io/2016/09/14/batch_normalization/
最终目标
- f: BN之后的整体输出结果
- y:对normal之后的线性变换(gamma + beta)
- x’:normal的input
- mu:batch mean
- varbatch vatiance
- 需要求 df/dx,df/dgamma,df/dbeta -> 最终结果整体速度比以前快了x2.5左右,这一步的主要目的就是用来提速的
可以把整体的计算分为以下的三个步骤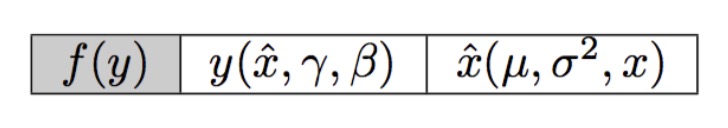
这三部分的代码如下
1 | def batchnorm_forward(x, gamma, beta, bn_param): |
Fully Connected Nets with Batch Normalization
in cs231n/classifiers/fc_net.py, add the BN layers into the net.
- 应该在每个relu之前加上BN,所以在这里不能直接用之前的affine,relu的过程,因为中间又插了一个新的BN层,所以要写一个新的function
- 最后一层之后的输出不应该BN(应该是涉及到循环的问题)
实现中遇到的问题
- self.bn_params的参数类型不是dict而是list,代表的是所有层里面的参数的所有和,当进入到每层的时候具体对应的才是这里的dict
- 当把affine_BN_relu结合在一起的时候,注意最后一层输出的地方没有BN,所以没有他的cache,需要分开讨论,不然cache的数量不对
- 注意这个fc_net的class因为需要实现多种不同的功能,所以对于是不是BN要加上条件判断
- 确实非常像搭乐高了!!
- 这里主要,写到这才发现最后一层的时候好像是不需要relu也不需要batchnorm
定义好的函数块
1 | def affine_BN_relu_forward(self, x, w, b, gamma, beta, bn_params): |
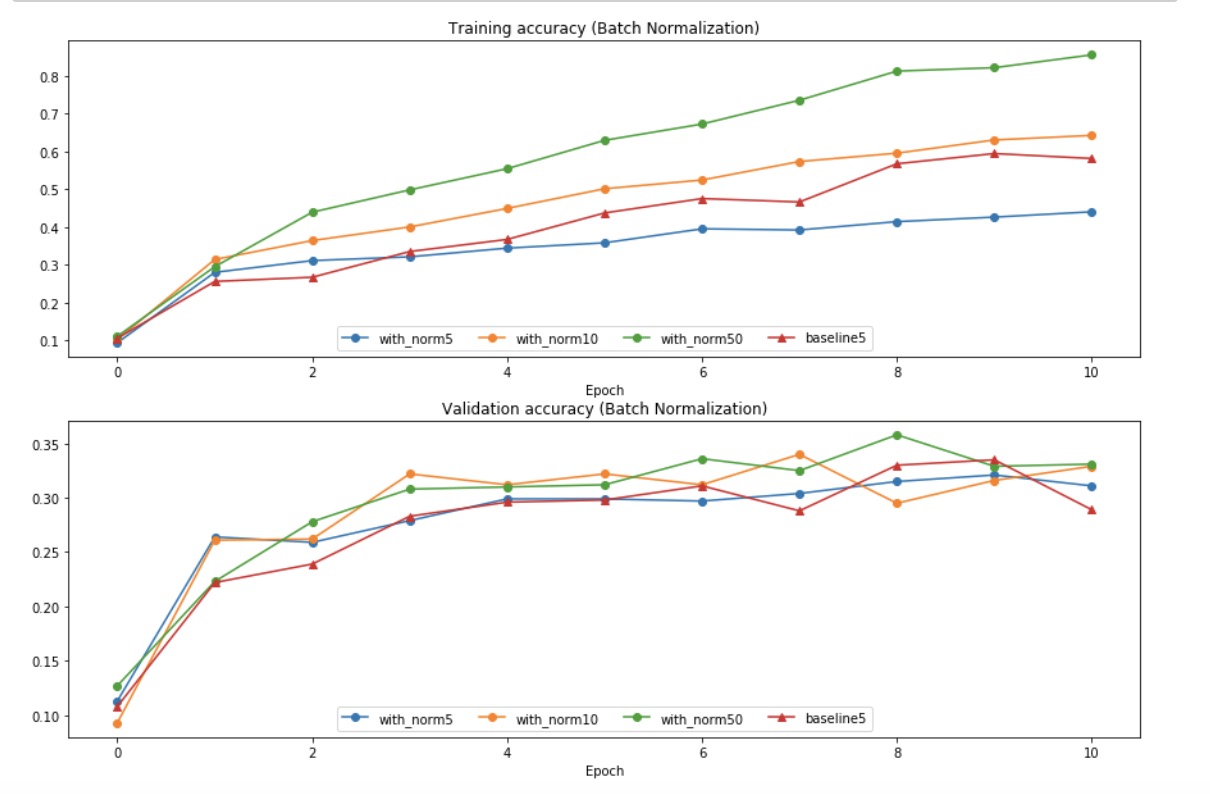
结论
- 可视化之后可以发现加了norm的话好像会下降的快一点
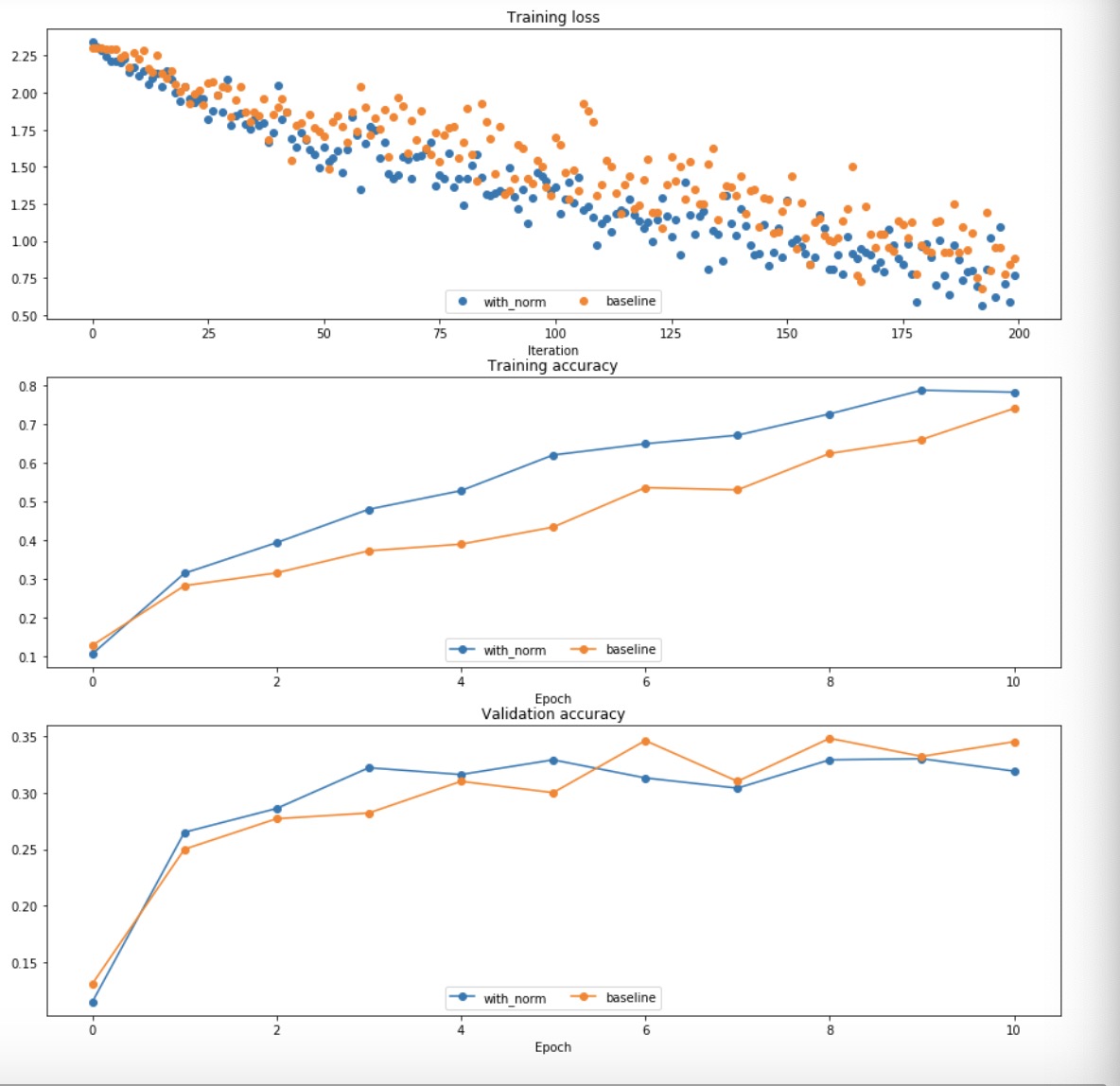
Batch normalization and initialization
- 进行试验,了解BN和weight initialization的关系
- 训练一个八层的网络,包括和不包括BN,用不同的weight initialization
- plot出来train acc, val_acc,train_loss和weight initialization的关系
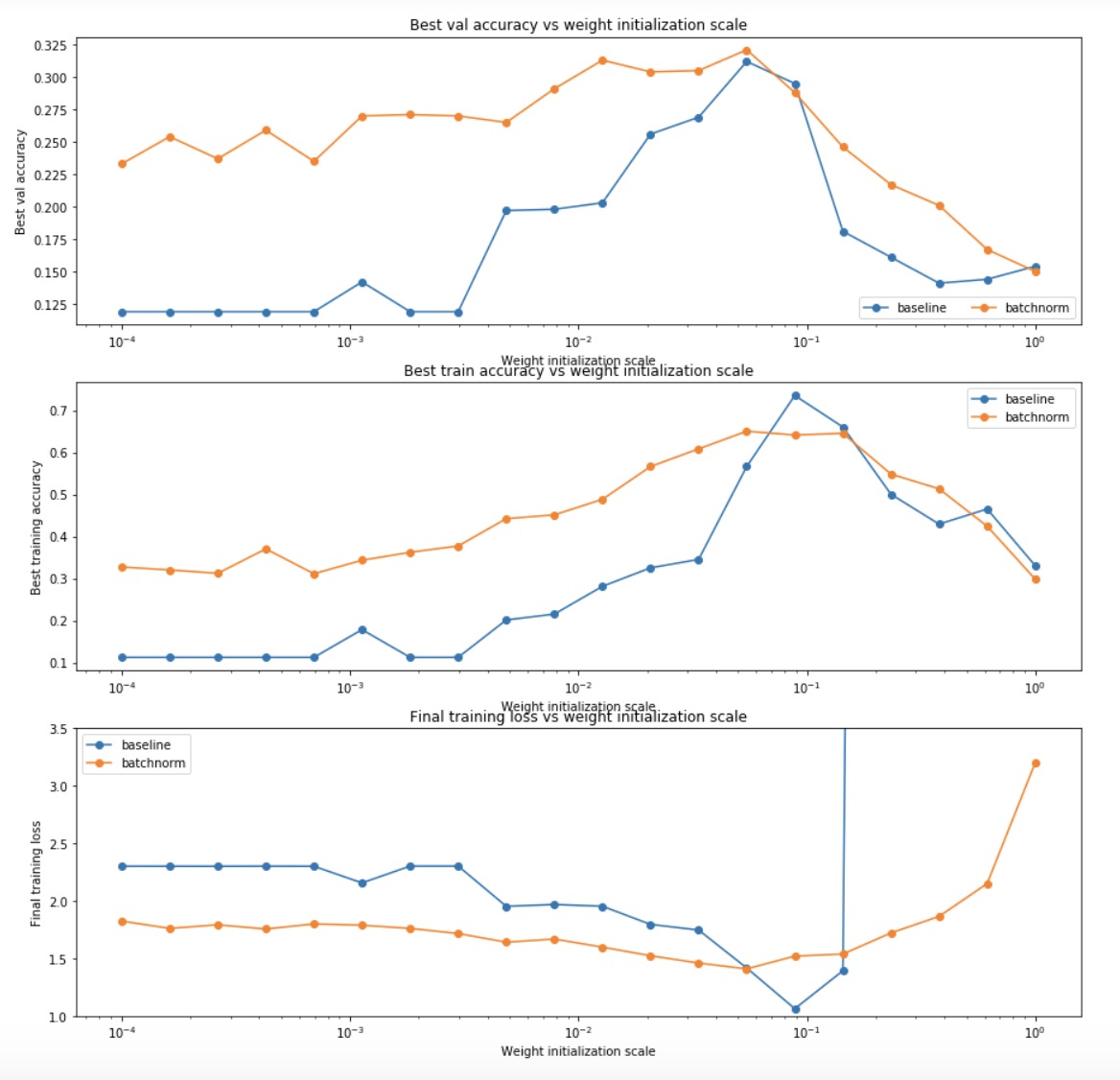
BN的作用
从图中可以看出来,有了BN以后,weight init对最终结果的影响明显会降低:
- weight的初始化对最终结果影响很严重,比如如果全是0的话,得到的所有neuron的功能都是一样的
- BN其实就是在实际中解决weight init的办法,这样可以减少初始化参数的影响
- 核心思想就是如果你需要更好的分布,你就加一层让他变成更好的分布
- 在计算的过程中越乘越小(或者越大),所以计算出来的结果越来越接近0
- 所以这时候如果把一些input重新分布了,就会减少这个接近0的可能性
Batch normalization and batch size
- 试验验证BN和batch size的关系
- 训练6-layer的网络,分别with和without BN,使用不同的batch size
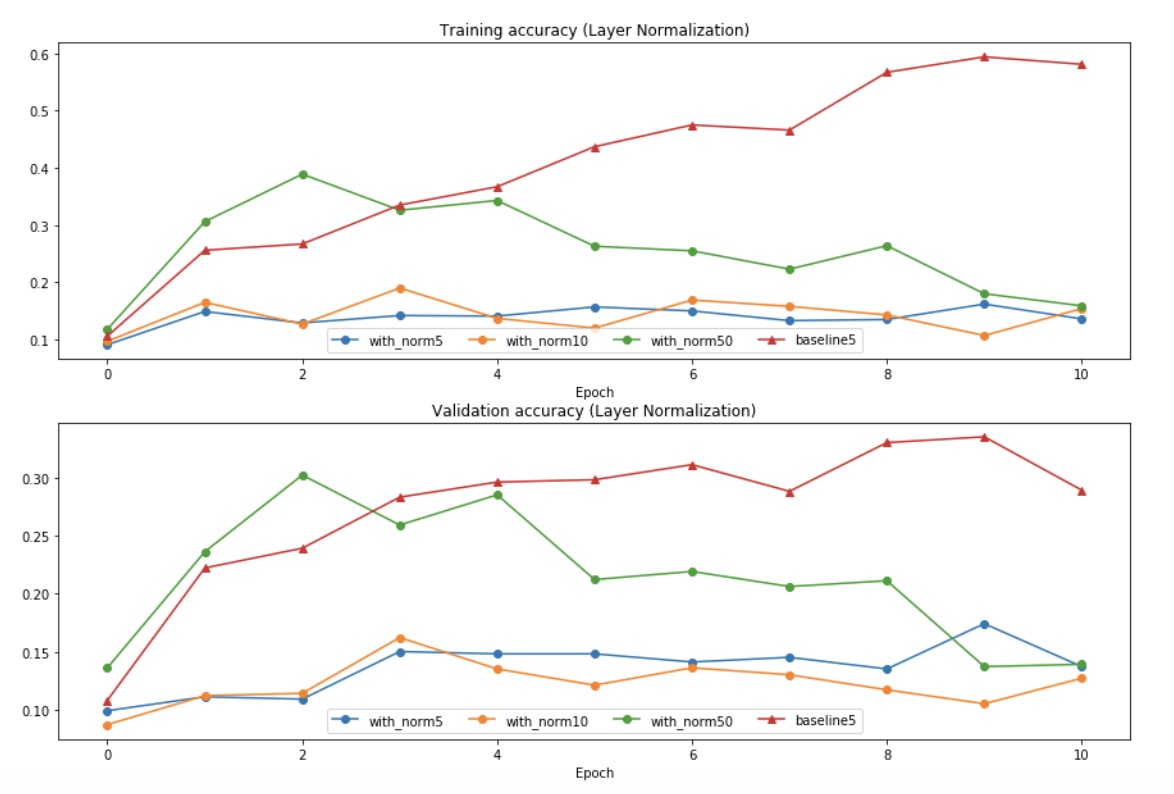
Layer Normalization(LN)
- 前面的所有的BN已经可以让Net更好的被训练了,但是BN的大小和batch的大小有关,所以在实际应用的时候会受到一些限制
- 在复杂的网络里面的时候,batch_size是被硬件机能限制的
- 每个minibatch的数据分布可能会比较接近,所以训练之前要shuffle,否则结果会差很多
其中一种解决的方法就是layer normalization
- 不是在batch上面normal
- 在layer上面normal
- each feature vector corresponding to a single datapoint is normalized based on the sum of all terms within that feature vector.
LN
- 综合一层的所有维度的输入,计算该层的平均输入和平均方差
- 然后用同一个规范化操作转换各个维度的输入
- 相当于以前我们希望可以正则到这个minibatch里面的大家都差不多,现在我们不管batch了,而是调整到一张图片里面的所有数据都是normal的
implement
cs231n/layers.py -> layernorm_backward
forward + back
- input
- x, (N,D)
- gamma, scale
- beta,shift
- ln_params: eps
output
- output,(N,D)
- cache
实现方法 -> 实际上就是从对一列的操作变成了对一行的操作
- 比如之前对x取mean就是求每列的mean,现在变成了取每行的mean
- 在所有normal之后并且scale之前,把这个矩阵在tranpose回来
- back
- 把需要参与计算的东西都tranpose
- 然后把计算完的dx tranpose回来
fc_nets
在fc_nets里面稍加改动,在normalization里面增加BN_NORM和Layer_NORM的选项就可以了,整体改动不大1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21def affine_Normal_relu_forward(self, x, w, b, gamma, beta, bn_params, mode):
a, fc_cache = affine_forward(x, w, b)
if mode == "batchnorm":
mid, Normal_cache = batchnorm_forward(a, gamma, beta, bn_params)
elif mode == "layernorm":
mid, Normal_cache = layernorm_forward(a, gamma, beta, bn_params)
out, relu_cache = relu_forward(mid)
cache = (fc_cache, Normal_cache, relu_cache)
return out, cache
def affine_Normal_relu_backward(self, dout, cache, mode):
fc_cache, Normal_cache, relu_cache = cache
da = relu_backward(dout, relu_cache)
if mode == "batchnorm":
dmid, dgamma, dbeta = batchnorm_backward_alt(da, Normal_cache)
elif mode == "layernorm":
dmid, dgamma, dbeta = layernorm_backward(da, Normal_cache)
dx, dw, db = affine_backward(dmid, fc_cache)
return dx, dw, db, dgamma, dbeta
可以从图像看出来,layernorm中,batchsize的影响变小了