Target
- regularization NN
- randomly setting some features to 0 during forward pass
Dropout forward + backward
in cs231n/layers.py
IO
- input
- x,input data, of any shape
- dropout_params
- p,每个neuron是不是保留的可能性是p
- mode:’train’的时候会进行dropout,‘test’的时候会直接return input
- seed:用来generate random number for dropout
- output
- out, 和x同样大小
- cache, tuple(dropout_params, mask). In training, mask is used to multiply the input
- 在实现中不推荐用vanilla的方法
1 | NOTE: Please implement **inverted** dropout, not the vanilla version of dropout. |
实现
- 在训练的时候在hidd层都drop了一部分,如果愿意的话也可以在input层就drop
- 在predict的时候不再drop了!但是需要根据drop的比例对output的数量进行scale -> 所以这样就会变得很麻烦(vanilla的方法)
- 比如比例是p,drop之后剩下了px
- 那在test的时候x的大小也应该变成px(x -> px)
inverted dropout,在训练的时候就对大小进行放缩,在test的时候不接触forward pass
1
2H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = (np.random.rand(*H1.shape) < p) / p # /p!!!back的实现更容易了,如果这个点被drop了的话对再往前的dx就没有影响,如果这个点没有被drop的话对之前的影响就是常数
code
1 | def dropout_forward(x, dropout_param): |
FC with DP
- 应该在每层的relu之后,增加dropout的部分
- 在之前定义的function里面加上新的dropout部分,因为倔强的想加在定义好的函数里面,所以产生了一些奇怪的延伸问题
- 如果想要可选参数,在def function里面直接定义好就行了
- 如果返回值不需要,直接在返回的时候
_就好了 - 注意在
fc_net里面如果dropout = 1 的话,实际上的flag是没有意义的
1 | def affine_Normal_relu_dropout_forward(self, x, w, b, mode, gamma=None, beta=None, bn_params=None): |
regularization experiment
- 训练一个2层的网络,500个training,一个没有dropout,另一个0.25的dp
- 并且可视化了最终的结果
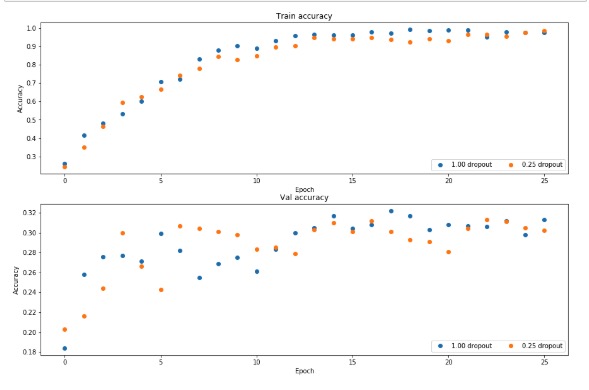
从结果上来看感觉,如果epoch比较少的话,dropout的效果会更好
加上dropout,normalization,的fc网络全部代码
1 | class FullyConnectedNet(object): |