target
In this exercise you will implement a vanilla recurrent neural networks and use them it to train a model that can generate novel captions for images.
Microsoft COCO
- 在这次的作业里用的是Microsoft的coco dataset,已经是一个很常用的给文字配上说明文(captioning)的dataset了,有80000个训练和40000个val,每个图片包含一个五个字的注释
- 在这个作业里已经preprocess了data,每个图片已经从VGG-16(ImageNet pretrain)layer 7提取了feature,存在了
train2014_vgg16_fc7.h5和val2014_vgg16_fc7.h5 - 为了减少处理的时间和内存,feature的特征从4096降到了512
- 真实的图片太大了,所以把图片的url存在了txt里面,这样在vis的时候可以直接下载这些图片(必须联网)
- 直接处理string的效率太低了,所以在caption的一个encoded版本上面进行处理,这样可以把string表示成一串int。在dataset里面也有这两个之间转换的信息 -> 在转换的时候也加了更多的tokens
事先看了一下图片和对应的语句

RNN
- 在这章要用rnn language model来进行image captioning
cs231n/rnn_layers.py
step forward
vanilla RNN的single timestep,用tanh来激活。输入data的大小是D,hidden layer的大小是H,minibatch的大小是N
- 输入
- x(N,D)
- prev_h:前一个timestep的hidden (N,H)
- Wx:input- to- hidden connections (D,H)
- Wh:hidden-to-hidden connections (H,H)
- b:bias,(H,)
- 返回(tuple):
- next_h:下一个hidden state,(N,H)
- cache:back需要的数据
- 构成:
- RNN用的就是上一个的h,这一个的x同时乘以不同的参数,合在一起预测这一次的h
- 对于某个时间点上的输入,还需要上一个的state h,参数W,乘在一起得到新的state
- 这个参数的W无论在哪个步骤里面使用,一直都是一样的
1 | def rnn_step_forward(x, prev_h, Wx, Wh, b): |
step backward
- 输入:
- dnext,下一个state的loss的gradient,(N,H)
- cache
- 输出:
- dx:input的gradient,(N,D)
- dprev_h:前一个hidden state的gradient,(N,H)
- dWx:Wx的gradient,(D,H)
- dWh:Wh的gradient,(H,H)
- db:bias的gradient,(H,)
- 其实这个求起来gradient更简单了,因为每一个的导数都很好求,搞对了矩阵的形状就可以了
1 | def rnn_step_backward(dnext_h, cache): |
forward + backwoard
- 刚才只是实现了每一步的forward和backward,现在要实现整个的这个过程了
forward
- 假设输入的是一系列由T个vector组成的,每个的大小是D
minibatch的大小是N,hidden的大小是H,返回整个timesetps里面的hidden state
输入
- 整个timestep里面的数据x(N,T,D)
- h0,初始化的hidden state(N,H)
- Wx (D,H)
- Wh (H,H)
- b (H,)
- 输出
- h整个timestep里面的states(N,T,H)
- cache
- 实际上就是首先设置了最开始的输入h0,然后在时间循环T里面不停的调用上面已经写好的step的函数,更新prev_h,把不同的值存在cache里面
- 注意h需要初始化!!
backward
- 输入了dh和cache,需要输出所有东西的gradient
- 思路主要是每一个step里面是加的关系,所以对于dWx,dWh和db来说,需要在每次遍历里面加上之前的值,相当于每次都需要加上新的东西
- back的时候需要next的时候来求现在的,然后在下一轮把next更新成现在的
1 | def rnn_forward(x, h0, Wx, Wh, b): |
word embedding
在深度学习的系统里面主要是用vector来表示单词的,字典里面的每一个都会关系到一个vector,然后这些vectors会和系统的其他部分一起学习
在这部分需要把int表示的单词转化成vectors
- 理解
- 在一句话里面,一个单词就是一个维度,而word embedding的核心就是降维
- 把字组成段落,然后用段落来总结出来最后的核心内容
forward
- 一个minibatch的大小是N,长度是T,把每个单词给到一个大小是D的vector
- input
- x (N,T)一个N个数据,每个数据里面T个单词,T给出来的是单词的indice
- W (V,D)给所有word的vectors
- return
- out:(N,T,D)给所有单词一个D的vector
- cache
backward
- back的时候不能back到word(因为是int),所以只需要得到embedding mat的gradient
1 | def word_embedding_forward(x, W): |
Temporal Affine layer
- 在每个timestep的时候,我们需要一个affine来把RNN的hidden vector转换成每个单词在vocabulary里面的scores(原来是根据这个来评分的,然后每次选出来一个合适的单词)
- 因为和之前做过的一样,所以直接提供了
Temporal SOftmax loss
- 在RNN的结构里面,每个timestep会生成一个对于vocabulary里面所有单词的score(矩阵)
- 在每步里面都知道ground truth,所以用softmax来计算每一步的loss和gradient,然后计算一个minibatch里面所有时间的平均loss
- 因为每个句子不一定一样长,所以在里面加上了
NULL的token,让所有东西一边长,但是在计算loss的时候不希望计算这个NULL。所以还会接收一个mask来告诉这个函数哪个地方需要算哪个地方不需要算
RNN for image captioning
- 在
cs231n/classifiers/rnn.py里面,现在只需要考虑vanialla RNN的问题 - implement loss里面的forward和backward
IO
- 输入
- image features,大小是(N,D)
- captions:gorund truth,大小是(N,T)其中每个元素应该都在 0-V之间
- 输出
- loss
- grads
TODO
- affine trans,从图片的特征计算初始化的hidden state,输出的大小是 (N,H) -> W_proj,b_proj -> 这一步初始化的是h0,也就是最开始的状态
- word embedding,把输入句子的int(表示在voca里面的位置)转化成vector,输出结果是(N,T,W)
- vanilla RNN(或者后面的LSTM)来计算中间的timestep里面hidden state的改变,输出结果(N,T,H)
- temporal affine来把每一步的结果转化成在vocabulary上面的score,(N,T,V)
temporal softmax把score转化成loss,注意需要忽略mask上面没有的
在back的时候需要计算loss关于所有参数的gradient,存在上面的dict里面
- 实际上直接按照之前写好的一直操作就可以了!
1 | def loss(self, features, captions): |
overfit small data
- 和之前一样,写了一个solver来计算,包括了训练model的所有需要的东西,在optim..py里面有很多不同的update的方法
- 可以接受train或者val的data和label,可以得到训练或者val的acc。在训练之后这个model里面会保存最好的参数,让val最低
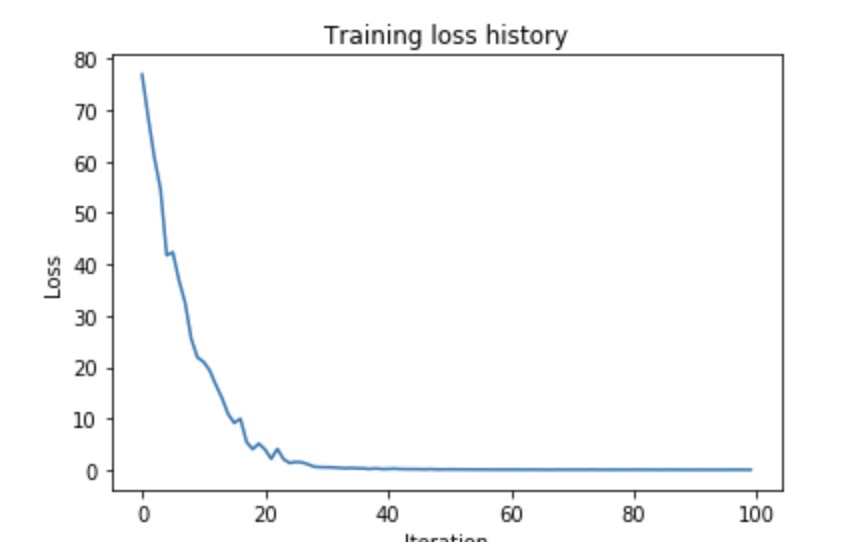
- 在这一步里面,载入了50个coco的训练数据,然后对一个model进行训练,最后得到的loss会小于0.1
test-time sampling
- 和分类不同,RNN训练和测试得到的结果会非常不相同
- 训练的时候,我们把ground-truth放进RNN
- 测试的时候,我们会sample出来每个timestep的单词的分布,然后把这些分布再喂到下一个step里面
implement
在每次step里面,我们把现在的单词embed,和前一个hidden state一起输入进RNN里面,得到下一个hidden state,然后得到vocabulary上面的score,选择最有可能的单词然后根据这个单词得到下一个单词
- 输入:
- features (N,D) 还没有进行projection的数据
- max_length:最长的caption的长度
- 输出
- captions (N,max_length),里面放的是0-V的int,第一个应该是
- captions (N,max_length),里面放的是0-V的int,第一个应该是
- TODO
- 需要把features初始化,然后第一个输入的单词应该是
(最开始) - 在之后的每一步里面
- 用已经学习好的参数,embed上一个单词
- RNN step,从上一个hidden和现在的embed得到下一个hidden(需要call每一步的函数而不是完整的函数)
- 把下一个转化成score
- 在score里面选择最有可能的单词,写出来这个单词的index,
- 为了简单,在
出现之前不用停止
- 需要把features初始化,然后第一个输入的单词应该是
- 注意:
- 应该用的是affine来计算score而不是temporal,因为要计算的只是现在这个范围里面的score,计算出来的大小应该是(N,V),所以应该在每行找到最合适的
- 每一步计算出来的最大值应该记在相应step的列上

1 | def sample(self, features, max_length=30): |