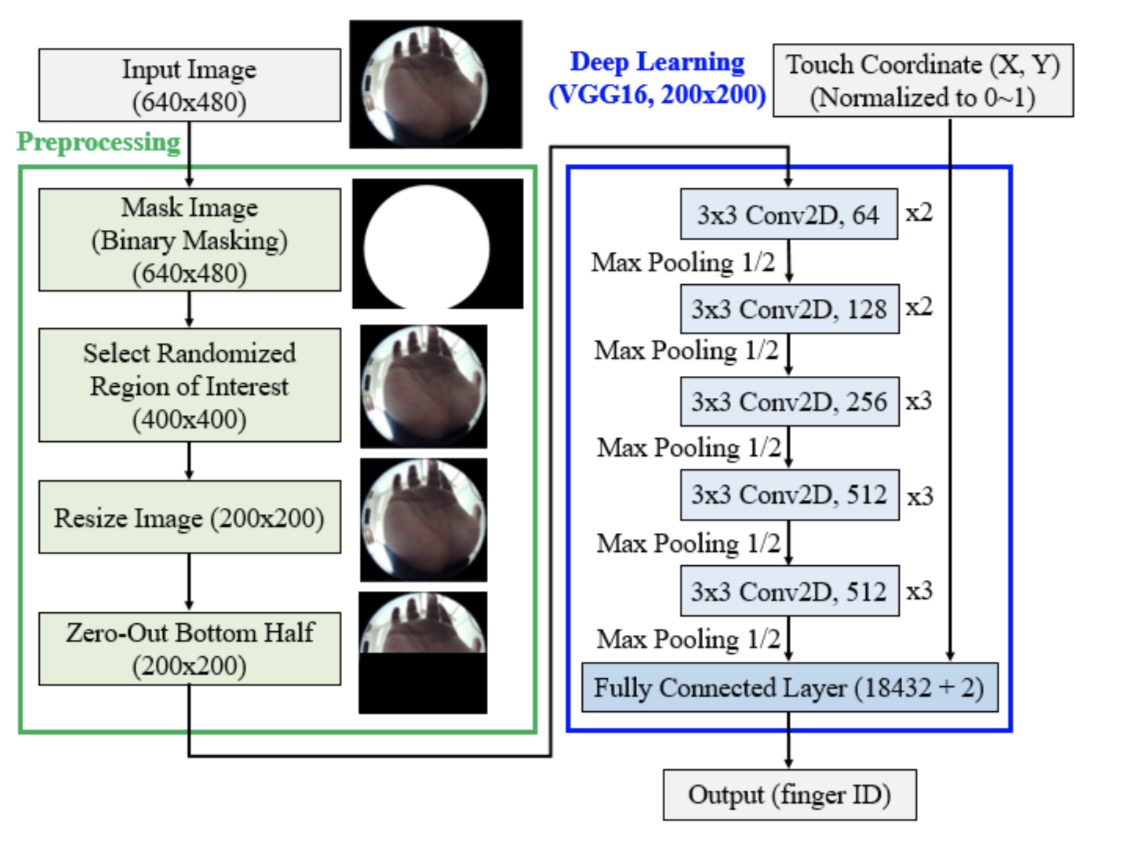
编辑距离
- 编辑距离是衡量字符串相似度的距离
- 主要应用比如衡量DNA的相似性,衡量什么地方断字,文件的差异等等
基本操作
- 对于字符串里面的两个字母,有三种操作方法能让他们改变
- 插入一个新的字母
- 删除一个已经存在的字母
- 把现有的字母替换成其他字母
- 对于两个string,有四种基本的操作
- 第一种,不变 (比如ruopeng和fag)
- 原本的操作 ruopeng[0,6] -> fag[0,2]
- 变换之后 ruopen[0,5] -> fa[0,1]
- 因为最后一位相同,这个问题可以拆分成最后一个字母,和不包括最后一个字母的substring,这个问题就可以拆分了
- 第二种,替代 replace (比如 peng 和 zhou)
- 原本操作 peng[0,3] -> zhou[0,3]
- 变换之后 pen[0,2] -> zho[0,2] + replace(g -> u)
- 其中,替换的操作是一步,替换之后最后一位的字母相同,这个问题就可以拆分成更小的问题了
- 第三种,插入 insert
- 原本操作 peng[0,3] -> zhou[0,3]
- 变换之后 peng[0,3] -> zho[0,2] + insert(u)
- 首先,直接把这个问题里面的zhou拆分成了更小的问题zho,然后再进行一个插入操作(一步),使zho重新变成了u
- 第四种,删除 deletion
- 原本操作 peng[0,3] -> zhou[0,3]
- 变换之后 pen[0,2] -> zhou[0,3] + delete(g)
- 同时也可以尝试尝试删除掉前一个string里面的最后一个字母g,不再管里面的g,把这个字符串尝试变成pen来进行比较
- 第一种,不变 (比如ruopeng和fag)
核心思想
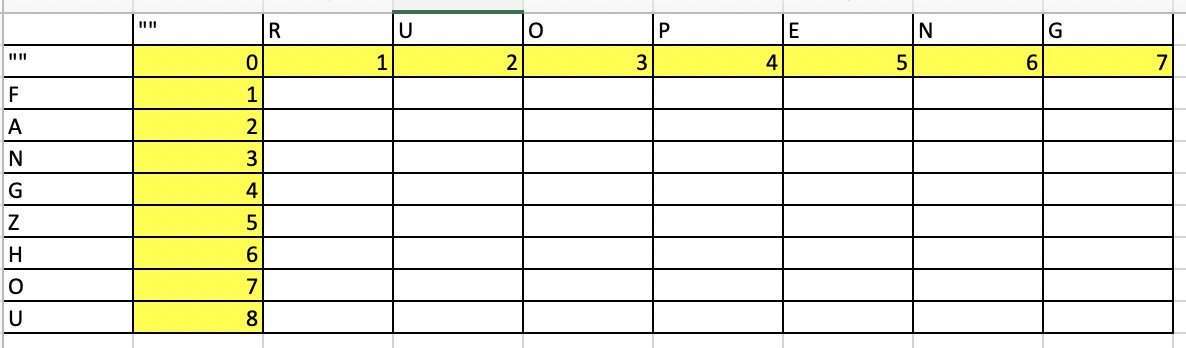
- 首先,我们针对这两个string制作一个table
- 对于这个表来说,每一个位置都相当于这个位置对应的两个substring的相似程度,比如E和F对应的就是 ”RUOPE“ 和 ”F“两个substring对应的相似度
- 在每个单词开始之前,还有一个空白符号,对应的substring就是空白。比如空白符号这一列对应的就是”“分别和”F“,”FA“,”FAN“等元素的比较

- 对于每个表格里面的位置,从(1,1)开始,这个位置和周围位置的关系如下
- 上面一格是插入,指的是在FANGZHOU这个string的substring里面插入
- 左边一格是删除,指的是把RUOPENG这个单词删除一个字母
- 左上角一格是替代,指的是把这两个单词的字母分别退一位。如果当前位的字母相同,当前位的值等于退一位之后的值,如果当前不同,是退一位的值+替代花费的操作(也就是1)
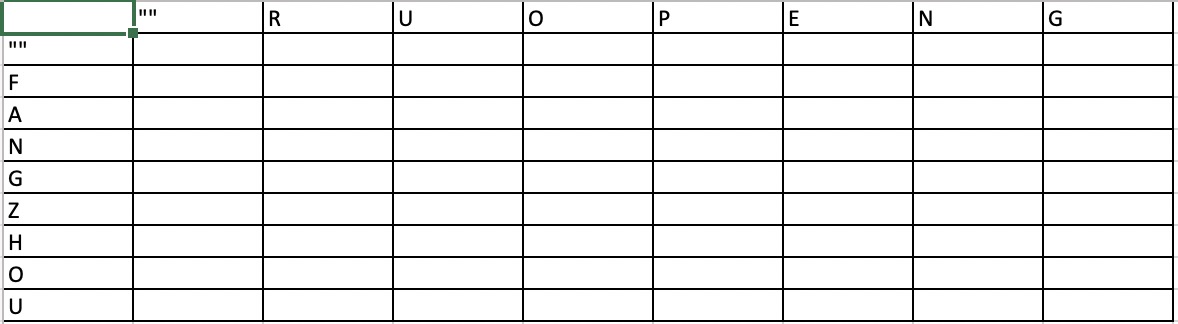
- 表格初始化
- 首先需要确定这个表格的边缘情况,也就是横坐标和纵坐标分别是0的部分,这个部分不能用上面总结出来的公式表示
- 因为这部分其实就是把不同的substring和空白符号比较,那么需要的最小操作就等于当前字母的位数
- 填表
- 从当前的初始状况出发,逐渐把这个表填完,每一个新的格子的值都取决于上一个格子的值
- insert = M[i-1][j]+1
- delete = M[i][j-1] + 1
- replace = M[i-1][j-1] + 1
- dont change = M[i-1][j-1] (两个字母匹配)
- 如果两个字母不匹配的时候,now = min(insert,delete,replace)
- 最终结果如下,红色部分为字母相同部分
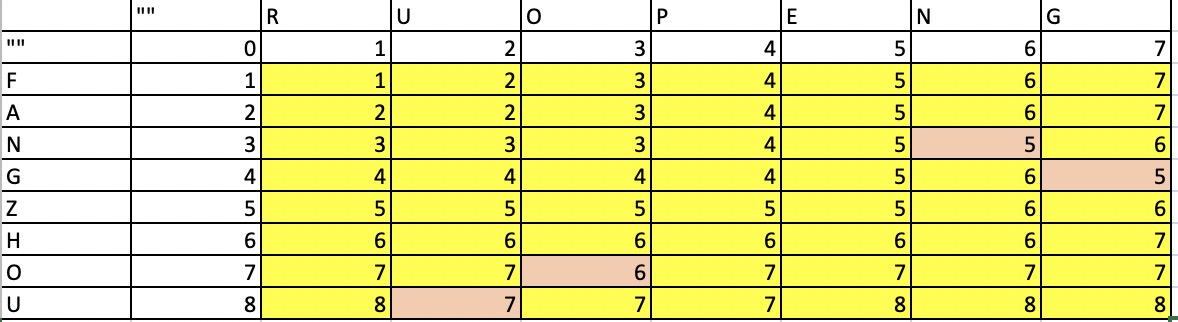
- 从当前的初始状况出发,逐渐把这个表填完,每一个新的格子的值都取决于上一个格子的值
python代码实现
1 | def EditDistance(a, b): |
- 注意分清矩阵的行和列,在这个实现里a是行,b是列
- 考虑到最前面的空字符串
- 注意从string里面读取的时候要记得减1
- 注意构建矩阵的时候行数和列数要加一
- 右下角的结果就是两个完整字符串对比的结果
时间复杂度
- 这个方法需要遍历左右的substring的组合,并且把所有的结果都存在一个矩阵里
- 如果两个string的长度分别是m和n,那么时间复杂度O(mn),空间复杂度O(mn)